03 Jul 2017
I love a good tech structure discussion at work and there’s one that’s been rumbling on and off for years that prompted one of my colleagues to exclaim the phrase that became the title of this post – “We’re not building The Matrix”. The debate is about how much autonomy an object/entity/game object/component should be given and ultimately how to structure the logic of a program.
Autonomous Monty
Firstly let me clarify what I mean by autonomy; the level of autonomy of an object is a measure of its ability to take decisions and to execute code based on those decisions. Let’s use the example of a simple 2 state enemy AI guard (called Monty). Monty has the following states and behaviour:
- If Monty cannot see the player he is patrolling.
- If he sees the player, he is attacking.
If Monty is designed autonomously he is responsible (by him I mean the code that comprises the entity “Monty”) for checking if he can see the player and for taking the appropriate action. Now it doesn’t matter if this behaviour is coded directly into the entity or whether the behaviour exists via components attached to the entity or any other way we wish to build Monty; ultimately Monty has been given the ability to make a decision (execute code) based on whether or not he can see the player. There is a certain allure with this type of design as it maps quite nicely to how people operate in the real world, however I believe (as did my colleague who made the Matrix reference) that building programs this way quickly leads to control flow issues, lack of flexibility and fragile codebases.
Through the Keyhole
For the rest of this post let’s assume that Monty is a single MonoBehaviour attached to a Unity GameObject and that he has his own update loop (called by Unity when the GameObject is active) that runs his behaviour. The problem is that up until now we have been considering Monty almost in isolation (my colleague describes this rather brilliantly like “programming through a keyhole”)…
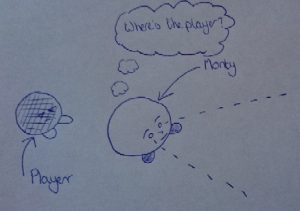
…but if we think about the bigger picture…
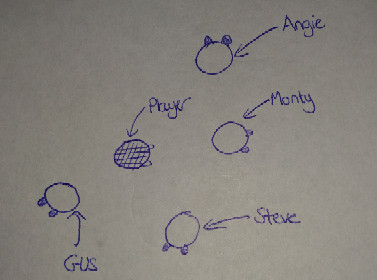
…Ok. So Monty has a bunch of mates who are also guards. This makes sense “where there’s one there’s many” right? Let’s add some complexity and see how our structure holds up:
Complexity modifier 1: The game designer slides over and tells you that the player can now become invisible and when invisible cannot be seen by “Monty” or any of his patrolling pals. You’re not worried, Monty can handle this:
Monty already has access to some of the player state right? At the very least the player position in order to decide whether he can see the player or not. We can just give Monty access to the data that states whether the player is invisible or not and use that to influence his decision – job done, ticket closed. However something rankles a bit because the player is invisible to all patrollers and yet all of them are now checking every update loop whether the player is invisible or not. Never mind it’s not that big of a deal.
Complexity modifier 2: The designer enters stage left and whispers in your ear that the player now has a flash-bang grenade that when deployed will disable guards and allow the player to be “invisible” to any guards in an unspecified radius for an unspecified time period. Hmm, a little more tricky:
Ok, so we subscribe Monty and his friends to an event that is triggered whenever the player uses a flash-bang. Monty can then check if he is within the unspecified radius and start a timer during which he will consider the player invisible. Seems pretty elegant.
Complexity modifier 3: The designer apparates behind you and declares that focus tests have found that the flash-bang is too powerful and has made the game too easy. It is being swapped out for a “McGuffin” which is a new weapon that will fire sleeping darts at the closest 2 guards – same result as the flash-bang, the player will be invisible to sleeping guards for a certain time period.
No problem, clickety-clack of the keyboard and Monty now knows about all his friends and their locations and they all know about him and they all listen to the event on the player and when the event is triggered they all calculate who is closest to the player and two of them come to the conclusion it is them and put themselves into the “sleep” state and start their timers, right?
Okay so that’s a bit of a contrived example and no-one would really design a system in that way surely? Let’s make it simpler, let’s pretend that Monty isn’t a hotshot, AI guard but instead a humble UI button (well he is a MonoBehaviour that exists on a UI object that has a button component and is hooked up to the button click event – but you get the gist). Monty has one job; when he is pressed he presents a pop-up to the user – simples. Monty is very good at his job, every time he is pressed he dutifully presents his pop-up. Doesn’t matter if another pop-up is already being shown, doesn’t matter if the player is mid-tutorial and Monty just happens to be on-screen, doesn’t matter that he might break the game flow. It’s not Monty’s fault, it’s not that he doesn’t care, it’s that he doesn’t know!
All jokey examples aside, that is why this kind of autonomous programming is bad. How many projects have you worked on where an object took some action that broke the program flow because the object did not first check the state of the program before modifying it in some way (a la the Monty button)? Or when game rules end up scattered throughout the codebase with everything having access to the state of everything else and coupling turned up to 11?
In order to make a correct (informed) decision the object making the decision must have access to all the information. In the weapon example that information is the location of the player and the location of all guards. In the UI example it is the awareness of the state of the application and whether it is in a tutorial or whether a pop-up is already displayed (and what the rules are – do we delay showing our pop-up, do we hide the existing one, do we appear over the top?). We can give the autonomous objects access to that information but these objects then become large complex beasts, full of state checks and decision flow logic that is really above their pay grade. Not to mention getting access to that data can be tricky (how does Monty get access to the locations of all the other guards?).
Programs are typically structured as hierarchies – think about the basic Unity structure:
But having a hierarchy alone is not enough unless the decisions are made from the top (even if you add a “GuardManager” to the above example, that creates and holds references to all guards, it doesn’t help the flow if the guards are still calling the shots). The hierarchy should not just represent ownership, it should also reflect the flow of code execution. Think about any corporate structure, you might make suggestions to your boss but the decision on what you should work on is his/hers to take because he/she has access to the bigger picture. This repeats all the way to the root of the hierarchy, decisions should be taken by those who have access to all the information, if you only have access to some of the information and still take a decision (like poor Monty) then that’s when issues arise.
Control from Top to Bottom
Autonomy is an illusion because looking back over the code you can clearly see the constraints placed on autonomous objects by the rules of the application (e.g. “Don’t attack the player if he is invisible”, “Don’t show a pop-up if one is already showing”). When structuring a program, information can flow in the direction from the leaves to the root (“I’ve spotted the player” or “I’ve been clicked”) but execution of state manipulating code should always come from the direction of the root to the leaves (“Attack the player”, “Go to sleep” or “Show/hide a pop-up”). Doing this makes it easier to implement more complex logic rules that operate on a set rather than a single object (e.g. only put 2 guards to sleep, make the guards split up to flank the player’s position, queue a new pop-up until the other one has been dismissed). If we restructured the guard example above to defer all decisions to the “GuardManager” then we have no trouble implementing the “McGuffin” weapon; as the manager can easily determine the closest 2 guards to the player and notify them to “go to sleep”.
I feel that Unity (and despite my protests ChilliSource) encourage this kind of autonomous structure by giving entities/game objects update loops tied to the scene rather than an owning system. If we want to stop updating all guards we have to disable them all rather than just not updating the GuardManager that in turn doesn’t update the guards. We are encouraged to think of entities like self-contained actors in the world rather than as data/state in a system. If we want to use composition to build complex behaviours we can and we should; but choosing when to execute those behaviours is not the domain of the entity. The guard entity is really nothing more than data – a position and a state, if we choose to add methods for manipulating that state (e.g. move to, go to sleep, attack, etc) into the guard entity for syntactic sugar then fine as along as those methods don’t affect any state other than the internal state of the guard. If the guard wishes to attack the player he may pass information up the chain stating that he has attacked (or rather wishes to attack) the player but it is not the guard’s responsibility to remove health from the player directly (what if the player has a shield? What if the player is invincible during the tutorial?). The alternative is to add even more state to the guard and to toggle that state based on the state of the program (e.g. the tutorial is active so Monty you are blind until told otherwise) and that leads to even more complex objects.
Some Rules
Here is the crux of the above distilled into rules that I try to follow when structuring a program:
-
A system (I’m using the term system as a catch-all for logic and state) should only directly manipulate its internal state (in our example the GuardManager is a system and the guards are its internal data). Never change core state when you can’t see the bigger picture and never bypass the team leader and ask his/her team to do something directly – that’s bad form (and the lead (e.g. GuardManager) may know of rules or have access to information that the boss doesn’t!).
-
If a system wishes to manipulate state external to it (i.e. show a pop-up, decrease the player’s health, etc.), then it must make a request up the tree to do so (remember information flow is bi-directional).
-
Code (especially when it manipulates core state) should be executed by systems that have all the information (as specified by the application rules). These systems deal with the requests that are passed up the tree to them.
And that’s it. By ensuring that the flow of the application goes from the root to the leaves we have made it easier to apply game rules, enable/disable entire branches of the program and to perform operations on groups of data. Hopefully we also reduce bugs caused by mismanagement of game state. Ultimately when programming we have full control of the flow, rules and data of our programs why would we want to mimic the real world and all its problems? Unless, of course, we were building The Matrix.
13 Jun 2017
One of the interesting things about keeping a blog is reading back over your old posts. It’s a bit like coming across old code, sometimes I read things that I’ve written and find myself disagreeing with my past self, other times I cringe at how naive I was or at my lack of understanding of the subject matter. Those feelings often prevent me from writing or publishing new posts because I worry what others will think or what I will think in the future. It’s funny because there is no better indicator of self-improvement than looking back and realising how little you knew and it will probably be far more worrisome the day I look at old code and cannot see any room for improvement.
I’m sure everyone experiences that kind of retrospective cringe and there probably isn’t much you can do about it. The one feeling that you can tackle is guilt. I’m wracked with professional guilt. I feel guilty for not keeping my blog up to date and I feel guilty for not finishing any of the dozens of side projects I’ve undertaken over the years. I read blog posts saying how important it is to finish what you start and to get it out to the community, how you should finish one project before starting on another and what not finishing projects says about you as a developer. Ultimately I’ve decided to stop feeling guilty because 1) there’s more to life than programming and 2) who can be bothered? Seriously, who can be bothered nudging UI around the screen until it’s pixel perfect or adding dozens of audio queues or tracking down a crash bug on one particular device running some custom flavour of a really old Android version. If you want to do all that in your spare time then I applaud you; but frankly I do enough of that tedious stuff day-to-day at work. I don’t need to prove I can finish games in my spare time because I finish and ship games as a day job.
What I want to do in my spare time is have fun. I enjoy programming and I enjoy tackling new challenges. The best thing about programming at home is getting a chance to do something you wouldn’t do at work. Once you’ve solved the problem and completed the challenge, why bother with all the other stuff required to make it into a product. Here’s a list of some of the stuff that I’ve done in my spare time over the last year:
- Implemented a half finished top-down racer in Pico-8 (just to see what programming on the Pico-8 was like).
- Started learning functional programming and wrote a program that simulated turns of a simple battle game (with no graphics).
- Started writing a Gameboy emulator (to see how different it was from the Chip-8 one – turns out quite a bit different).
- Solved like half the puzzles on CodinGame using C, C++, Python or Scala.
- Wrote an AI bot to compete in one of those online battles (I won a couple of fights and lost a couple of fights but I was more interested in finding out how to host that kind of thing).
- Wrote a Python script to play Countdown (worked well for the letters but couldn’t always get the best number).
- Ported some of my early programming attempts from OOP to data oriented.
- Learned how they implemented the fire in Far Cry 2 and replicated it (without any visuals or actual fire).
The point of all these projects was to have fun and learn something new. Often the learning outcomes made me a better and more effective programmer in my day-to-day work, but some of the stuff I learned I’ll probably never use again – and you know what? I knew that at the time! It wasn’t the point.
So I’m not going to feel guilty for not finishing stuff or for having 6 projects on at the same time. However what I will do more of is blog about, and put on GitHub, some of my half-finished, half-baked projects, if for no other reason than so I can look back in 5 years and say of my past self “What were you thinking?”.
P.S: This should hopefully kickstart a run of blog posts about things that have been rattling round in my head for a while, but if it doesn’t then so what?
17 Mar 2015
Getting started…
I’ve long wanted to write an emulator for one of my childhood consoles either the Master System, Mega Drive or Gameboy, and recently worked up the energy to get started on one. I had a rough idea how to create an emulator but rather than cracking on foolishly with a more complex console, most emulation sites recommend starting with a Chip-8 emulator - so that’s what I did.
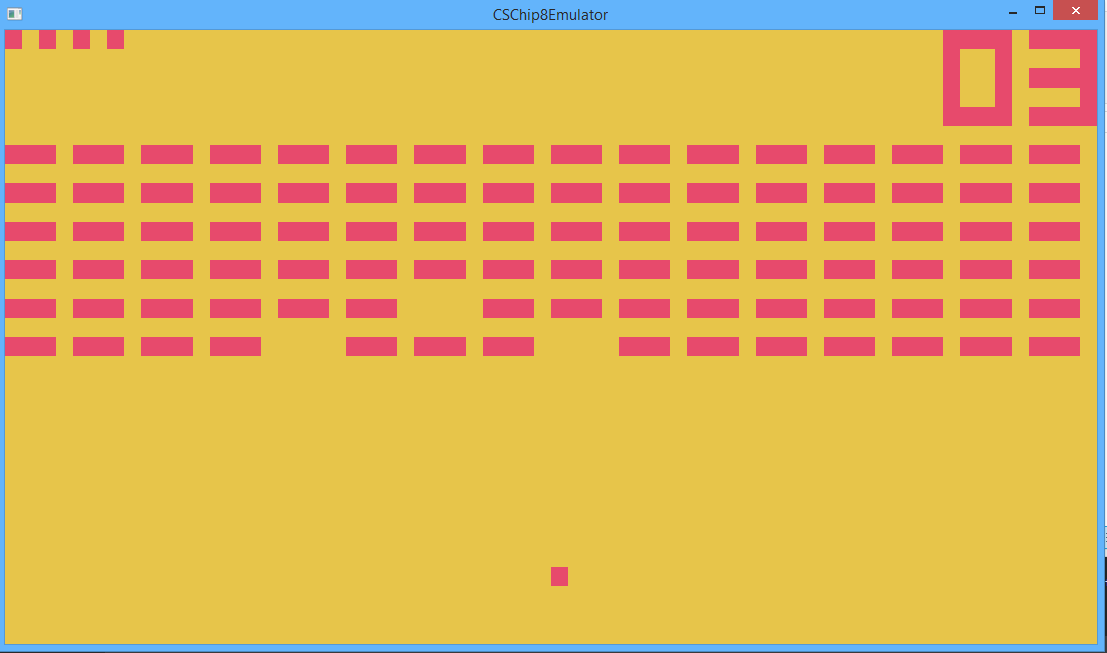
Chip-8 is not a physical machine but a virtual machine with an interpreted language. It is a very basic machine with only 2 colour graphics, 4k memory, 16k stack, 17 registers, 2 simple timers and 32 opcode instructions. Chip-8 has none of the features found in more complex consoles such as interrupts, sprites, memory banking, etc; and is therefore a good machine to use to learn about emulation. There are also a few game available freely online such as: Pong, Space Invaders, Breakout and other classics.
I’m not going to write in-depth about how to create a Chip-8 emulator, as plenty of good information can be found online:
Instead I’ll write about how I used Chilli Source to create this and point out some of the areas that tripped me up.
Getting the timings right…
When emulating a system, it is vital that execution and update timings are spot on. Unfortunately the Chip-8 specs are pretty vague on what these timings should be. Lots of reading around suggests that the timers and screen refresh run at 60Hz and the CPU executes either 60 or 600 opcodes per second. Let me tell you, I tried running at 6o opcodes and it was like pulling teeth, so I’d recommend going with 600.
In Chilli Source it is pretty easy to regulate update speed to 6o FPS by setting 60 as the preferred FPS in App.config and Application’s fixed update interval to 1/60. Then, in order to ensure the correct number of updates are performed, use OnFixedUpdate inside a state to drive the timers, graphics and the CPU’s fetch, decode and execute cycle:
void Chip8State::OnFixedUpdate(f32 in_dt)
{
if(m_paused == false)
{
m_keyboard.UpdateKeyStates(m_state);
m_cpu.FetchDecodeExecute(m_state);
m_renderer.Draw(m_state);
}
}
The above code ensures that the application runs at 60Hz but more is required to ensure the CPU executes 600 opcodes per second:
void Chip8CPU::FetchDecodeExecute(Chip8MutableState& inout_state)
{
for(u32 i=0; i<Chip8Constants::k_opcodesPerUpdate; ++i)
{
auto nextOpCode = FetchNextOpcode(inout_state.m_memory, inout_state.m_programCounter);
auto action = Decode(nextOpCode);
//Execute decoded action which will change the chip state.
action(inout_state);
}
//Timers are updated at 60Hz independently of opcodes.
inout_state.m_delayTimer = UpdateTimer(inout_state.m_delayTimer);
inout_state.m_soundTimer = UpdateTimer(inout_state.m_soundTimer);
if(inout_state.m_soundTimer > 0)
{
CS_LOG_VERBOSE("Beep!");
}
}
Pretty straightforward, if we know that this method executes 60 times per second then we should execute 10 opcode each time (in more complex systems this can be made more accurate using the opcode execution times from the specs).
Getting the CPU to do something…
The articles I linked to above cover opcode instructions pretty explicitly so I’m not going into detail about how to decode opcodes or what each opcode does (which is usually manipulating register data), however most the tutorials I have found online use a giant, nested switch statement to handle each opcode - this is less than ideal as it makes testing of each opcode messy (and you will need to test each opcode I can tell you).
Opcodes operate on graphics memory, standard memory, registers, the program counter and the stack; these can be combined into a struct and effectively hold the entire state of the VM. Creating a standardised opcode function signature that takes and manipulates the state allows each opcode to be implemented as a standalone function:
//Clear the screen
void x00E0(OpCode in_opCode, Chip8MutableState& inout_state)
{
std::fill(std::begin(inout_state.m_graphicsMemory), std::end(inout_state.m_graphicsMemory), 0);
inout_state.m_shouldRedraw = true;
inout_state.m_programCounter += 2;
}
//Jump program to NNN
void x1NNN(OpCode in_opCode, Chip8MutableState& inout_state)
{
inout_state.m_programCounter = C8_MASK_NNN(in_opCode);
}
//Jump to NNN and push the stack (call subroutine)
void x2NNN(OpCode in_opCode, Chip8MutableState& inout_state)
{
inout_state.m_stack[inout_state.m_stackPointer] = inout_state.m_programCounter;
++inout_state.m_stackPointer;
inout_state.m_programCounter = C8_MASK_NNN(in_opCode);
}
Now that each opcode has a functional representation it can be mapped to an opcode hex value and whenever that value is interpreted the correct function can be called. Opcodes are mapped on the first nibble i.e. 0x2000, 0x3000, etc. Rather than using a map or dictionary to pair the functions with the correct opcode I used an array and filled all the blanks in with an error function should an unknown opcode be executed:
//Fill with NoOps which are called for missing or unknown instructions
std::fill(std::begin(m_opcodeActions), std::end(m_opcodeActions), CSCore::MakeDelegate(&OpCodeActions::NoOp));
m_opcodeActions[0x00e0] = CSCore::MakeDelegate(&OpCodeActions::x00E0);
m_opcodeActions[0x00ee] = CSCore::MakeDelegate(&OpCodeActions::x00EE);
This isn’t the full story as some opcodes share the same first nibble, for example 0x8FF0, 0x8FF1, etc, and therefore will both fall through to 0x8000. 0x8000 is a routing function which checks the remaining bytes and routes to the correct function. Other routing functions include 0x0000, 0xE000 and 0xF000.
Ultimately this means there are at most 2 look-ups to find the correct function to call for an opcode.
Getting something on screen…
The Chip-8 has a resolution of 64x32, which is pretty small. Most tutorials recommend using glDrawPixels to blit to screen. This isn’t very platform agnostic so I prefer a more brute force approach that makes use of modern GPUs abilities to devour vertices - I create a sprite for each pixel.
Firstly I create an orthographic camera with viewport size 64x32 (in Chilli Source this defaults to fill the screen or window; this is what I want but obviously loses the aspect ratio). I then create 1x1 sprites tiled to fill the entire screen and set them to invisible. I set the scene clear colour to the desired background colour and each sprite to the desired foreground colour (in this case a garish fruit salad palette) and then simply hide and show sprites based on the graphics memory state (e.g. if gfx[1, 2] == 1 then sprite[0, 2] = visible). Simple!
Weirdly the Chip-8 has a hex keyboard (yep. 16 keys labeled 0 - F). Feel free to map these to a QWERTY keyboard any way you wish but I chose the following and used the Chilli-Source keyboard system to fetch the user input:
void Chip8Keyboard::UpdateKeyStates(Chip8MutableState& inout_state)
{
if(m_keyboard != nullptr)
{
inout_state.m_keyState[0] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_num1);
inout_state.m_keyState[1] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_num2);
inout_state.m_keyState[2] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_num3);
inout_state.m_keyState[3] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_num4);
inout_state.m_keyState[4] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_q);
inout_state.m_keyState[5] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_w);
inout_state.m_keyState[6] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_e);
inout_state.m_keyState[7] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_r);
inout_state.m_keyState[8] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_a);
inout_state.m_keyState[9] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_s);
inout_state.m_keyState[10] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_d);
inout_state.m_keyState[11] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_f);
inout_state.m_keyState[12] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_z);
inout_state.m_keyState[13] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_x);
inout_state.m_keyState[14] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_c);
inout_state.m_keyState[15] = (u8)m_keyboard->IsKeyDown(CSInput::KeyCode::k_v);
}
}
Getting it to make some noise…
The Chip-8 can only make a single, annoying, beep. If you check out the code in the timing section you should see that there is a sound timer that counts down at 60Hz. A couple of the online references get this wrong and it tripped me up too - the specs state that while the timer is greater than zero the beep plays. Not when the timer reaches zero, which is what a few of the online tutorials do. This makes things slightly harder as you have to either find a looping beep sound or a beep sound that’s duration is greater than 4.25 secs (timer max. is 255 and one is deducted 60 times a second) and then stop and start it based on the sound timer.
Getting the source code…
Now that I have cut my teeth on the Chip-8 I’ll move onto something a bit more meaty - probably the Gameboy or Master System. I’m going to finish off the Chip-8 emulator by adding a ROM picker and pause/reset buttons with the CS UI system.
Feel free to browse through the source code to check out how to implement all the opcodes CSChip8Emulator
12 Mar 2015
Originally posted on Gamasutra
Last month, Tag Games launched our game development engine, at Pocket Gamer Connects in London. The engine is called ChilliSource and is available under the MIT license as a free, open-source solution for creating games.
At Tag, we have long understood the benefits of using and contributing to open-source software, but I was surprised that many developers I speak to see open-source solutions as a risky choice, or know little about the advantages of using open-source software. Having been involved in the ChilliSource venture from day one, it feels like a good opportunity to share some of the reasons Tag use open-source solutions (focusing on game engines) and ultimately what lead us to open up our internal technology in this manner.
Background: The trouble with closed-source…
To date, ChilliSource has been used by Tag Games to create eleven titles on a range of platforms. However, prior to ChilliSource, we used a popular closed-source engine to develop most of our games. We didn’t really have any major issues with the engine itself, but its closed-source nature provided some concerns.
So what do I mean by ‘closed-source’ and ‘open-source’? Really the difference between closed and open source is in the licensing approach; and there are lots of different licenses! For example, it’s possible to have software where you can see the code but not edit it, or edit it but not re-distribute it, or do what ever you like with it. In the context of this blog I’ll make the distinction that you can view, edit and update the code of an open-source project (i.e. MIT license) but cannot do the same on a closed-source one.
With closed-source software you are basically at the mercy of the software vendor. Often this is fine because it is in the vendor’s interests to keep the customer happy with new features and bug fixes; but the problem arises around the issues of time and priority. The features and fixes that the vendor will focus on are those requested by the majority of the community (that’s where the money is right?); this could mean the bug fix you require is at the bottom of the pile. This might be, at best, a minor inconvenience or…it could be you have a release deadline in 2 days, a whole bunch of advertising booked and absolutely no way of fixing your bug in order to meet that deadline. Worst of all the third party company could have their software acquired, potentially stopping support or limiting deployment platforms for your future games.
We’ve had a few issues like this at Tag, where the support team of a third party technology couldn’t possibly work to the timescale we required, and particularly in the case of an engine that’s enabling all of your games (and possibly all of your company’s revenue), this can be a scary prospect. This became such a concern for the company that the team were tasked with finding an engine that would allow us to address these issues ourselves. Unfortunately at that time smartphone gaming was still in its infancy and there were no open-source solutions available that met the requirement of iOS and Android support, plus 2D and 3D rendering. As a result ChilliSource was born.
So what are the main benefits of open source?
Reason one: Taking control…
Control is the main reason that Tag moved away from a closed-source engine and I believe, above all else, that control is the main benefit of open-source software.
Handing control to your programming team means that you are no longer dependent on third parties for new features and bug fixes. If iOS has a new killer framework your team want to take advantage of to wangle a front-page feature on the App Store, then you can. If a bug is found in your live app and it needs to be fixed and updated ASAP, then there is no need to waste time to-ing and fro-ing with remote customer support. Open-source enables you to work to your own timelines and your own priorities
Control also has more far reaching implications than just bug fixes, it can allow you to add new platforms and open up untapped markets. Niche markets can potentially be quite lucrative for small, indie studios but are maybe not recognised by large vendors. Ultimately you get a say in the direction of the engine that you use to make all your games – that’s got to be a good thing.
ChilliSource is written in C++ and one of the main benefits of using a global language, in combination with open-source, is the wealth of available libraries and modules that can be plugged-in. You don’t have to be tied to a particular physics engine or networking library, for example; you can use tools that you are already familiar and comfortable with.
With open-source solutions no one can seize this control away from you. The source does not belong to an individual or company, it cannot be acquired; it belongs to you and the community.
Reason two: Seeing is believing…
Being able to edit and update the source is really powerful but just being able to see it also has huge benefits.
A common misconception is that open-source software is of poor quality. I’m sure there are many poor quality open-source projects out there but I’m equally sure many poor quality closed-source projects also exist. At least with open-source software you can audit it, perform your own code reviews and judge the quality for yourself. Just because a project is open-source does not mean that any old code can be contributed. Most open-source projects have strict guidelines and review processes that must be met before code can make its way into the main branch (however you can always fork the source and manage the code using your own guidelines and process if you wish).
Having the ability to examine the code means that, for example, if you want to know what type of encryption is used in the data store or what networking protocols are used in the multiplayer system, then you are not dependent on the documentation (which can often be non-existent or worse out of date); just open up the source file and see for yourself.
Reason three: Did I mention it was free?
Open-source software is free. I could have lead with this reason and that might have been enough to convince many of the merits of open-source (sometimes there are costs for services such as support but the software is free to use). One of the biggest expenses at Tag is kitting out new employees with expensively licensed software; this can be a huge barrier for smaller, indie companies often preventing them from growing and expanding. Switching to suitable free, open-source alternatives can save money and be hugely rewarding if you’re one of the passionate and dedicated developers contributing their expertise and time to free, open-source projects.
Reason four: Sharing and improving…
One of the main reasons for releasing ChilliSource to the wider industry is that we wanted to build a community. Opening your technology to the community allows you to engage with developers with different experiences, specialisms, needs and ideas and can drive your project forward in ways that you would never have thought of had you kept it in-house. It also gives you the opportunity to hire people who are already familiar with your tools and technology, rather than spending time and money training them.
Knowledge sharing is invaluable – whether you are a student looking to get your hands on source code for learning, a developer looking to make use of a product that takes advantage of an experienced and active community or a contributor looking to give back to the community and get feedback on their code. This is the power of an open-source community where knowledge, features and bug fixes are shared and everyone benefits.
Conclusion: Final thoughts
The games industry is hugely diverse with many talented and dedicated individuals, but it is also constantly evolving and changing. It is important for a company like Tag Games to stay agile and be able to adapt to changes. This need led us to take control of our own middleware by creating ChilliSource, but in order to tap in to the experience and diversity of the game development community we needed to open up this technology and share it with the community. We now have the ability to listen and act upon the ideas and work created by other developers using ChilliSource which will prove beneficial to us all.
If, like us, you want to have a say in the tools that you use to make your products (and ultimately your revenue) and you want to benefit from the experience, knowledge and dedication of a community; then I would really recommend investigating open-source as a viable alternative to licensed products.
Scott Downie, Lead Technology Programmer, Tag Games
16 Feb 2015

I read a lot of blog posts these days about the death of OOP, with flocks of programmers abandoning their objects in favour of DOD, reactive or FP (and probably other acronyms I’ve never heard of). I’ve been dabbling quite a lot recently with both DOD and FP and it’s easy to see why many people have embraced that style of programming, but when it comes to doing my day job I still always think in objects; I can’t help it and I also know I’m not alone.
Now, I still believe that object-orientation has a part to play in system design; as do all the other acronyms. There are no silver bullets in programming and all approaches have their own strengths and weaknesses; it’s about picking the best solution for the problem at hand.
The problem is, that despite all the recent bluster, I still don’t think many people know that there are any alternatives to OOP, let alone what their respective strengths are. I watched Mike Acton give a presentation on DOD at a C++ conference and the audience questions at the end led me to believe they all thought he was an absolute nut job. One of the questions that I ask graduates during interviews is what programming methodologies they like and what the strengths and weaknesses are and 90% of graduates answer OOP, strengths: encapsulation, abstraction, etc and weaknesses: O_o. Seriously, most of them have never even considered that there are any other types of programming, let alone weaknesses of OOP; to them OOP is programming. When I prompt graduates about the difficulties of multi-threading OOP applications they shrug “threading is hard”.
Even when you know and have used other programming methodologies it is still hard not to default to OOP. The worst thing is most of us have twisted OOP so far it doesn’t even look like OOP anymore - flat inheritance trees, composition, immutable objects, etc.
I like OOP but I think I, and others, like it too much and a large part of the blame falls on universities (and like so many of the worlds ills - Java). Most uni courses that I’ve seen (including the one I took) have 6 months of imperative training, maybe a little assembly and then blam! straight onto the objects for 4 years. All the course examples are OOP, frameworks are OOP, even marking guidelines deduct points for lack of OOP. Instead of all this brainwashing, teach a variety of techniques and allow students to work out what they like and don’t like for themselves. Ultimately it’s about picking the most appropriate techniques for getting the job done and getting home in time for tea - we can call it objective-oriented programming.
Now if you don’t mind I’ve got to go and send a empty message to this bin, it’s leaking its encapsulations all over the floor…